

TL; DR
- AI learns your voice by extracting acoustic features (pitch, timbre, cadence, breath pattern) from short audio samples, then training a model to reproduce them.
- Modern voice cloning needs as little as 30 seconds of clean audio for a passable clone. Studio-grade clones need 5 to 30 minutes.
- For corporate training and e-learning, the practical question isn't "how does AI learn voice" but "how do I keep the clone consistent across 200+ training modules over 18 months."
AI voice learning sounds like magic until you see the data behind it. Whether you are exploring basic AI voice cloning or advanced deep learning speech model generation, the technology relies on precise math rather than magic.
The first time a learning and development manager hears their own voice played back from an AI clone, the reaction is usually some version of "how did AI learn my voice that fast from 90 seconds of audio?" The second reaction, once the surprise wears off, is operational. AI that learns your voice is now a vendor category, not a research project.
The honest answer is that AI voice learning doesn't memorize your voice. It extracts a mathematical fingerprint of how you sound and learns to reproduce that fingerprint when fed new text. This AI voice fingerprint is built from features that human ears process unconsciously. Pitch range. Speech rhythm. Breath placement. The micro-pauses you take before specific consonants. The slight nasal coloring on certain vowels.
This piece walks through how AI voice learning actually works, what data it needs, where the limits sit in 2026, and what the trade-offs look like for teams using AI voices in corporate training, e-learning voiceover, and customer-facing applications.
AI learns your voice by analyzing acoustic features from short audio samples and training a neural model to reproduce them. This process applies whether you want an ai voice for corporate training videos or you want to build an AI voice agent. Modern voice cloning needs 30 seconds to 30 minutes of clean audio, depending on the quality target. The model extracts pitch, timbre, cadence, and breath patterns. Then synthesizes new speech matching those features when given text input.
What's actually happening when AI learns your voice
Voice cloning models in 2026 are built on neural architectures (mostly transformer-based) that process audio in two stages.
Stage one is feature extraction. The model converts raw audio into a high-dimensional representation called an embedding. This requires sophisticated voice model training. This is the same underlying mechanism behind how AI recognizes voice in security systems, where voice biometrics and speaker recognition AI identify a caller by their vocal signature instead of a password. The embedding captures everything distinctive about the speaker without storing the audio itself. Pitch range, formant frequencies (the resonance peaks unique to each vocal tract), speaking rate, and prosodic patterns (the melody of how sentences rise and fall).
Stage two is synthesis. When you feed the model new text, it predicts what audio waveform that text would produce if the same speaker said it. The prediction draws on the embedding from stage one plus a separately trained deep learning speech model. Modern neural voice synthesis systems run this prediction in near real time, which is why latency on a phone call has dropped from "noticeable delay" to "indistinguishable from human" over the past 18 months.
The L&D manager at one mid-market manufacturing firm spent her first week training day in front of a microphone in a converted broom closet because the AC unit in the main studio kept cycling on every 90 seconds. Like clockwork. The clone she produced from those samples ended up being the company narrator for 47 training modules.
How much data does AI actually need?
The honest answer is "depends on the quality target." Three tiers exist in 2026. Every tier is a tradeoff between voice model training time, audio volume, and final realism.
Tier 1: Quick clone (30 seconds to 2 minutes of audio)
Good enough for proof-of-concept work, internal demos, and short marketing snippets. The clone catches the speaker's general timbre and pitch range. It misses subtle emotional inflection and tends to flatten when handling unusual sentence structures. This is the tier behind every "AI learns voice from 2 sentences" headline you've seen.
Tier 2: Production clone (5 to 15 minutes of clean audio)
This is the practical zone for most AI voice for corporate training videos, e-learning narration, and onboarding modules. The clone holds up across long passages, handles emotional range, and stays consistent across recording sessions weeks apart. Teams shipping e-learning voice-overs at scale almost always land here.
Tier 3: Studio clone (30 minutes to several hours)
Reserved for situations where the voice will be the brand. Premium narration, audiobook production, hiring named voice actors for AI training, and licensing their voice for ongoing AI use. The clone matches the source so closely that listeners often cannot distinguish in a blind test. Most queries searching how to train ElevenLabs voice at this fidelity end up here, since the studio tier requires the kind of clean audio that only controlled environments produce.
How voice cloning tiers compare across use cases
This breakdown shows which tier fits which production context.
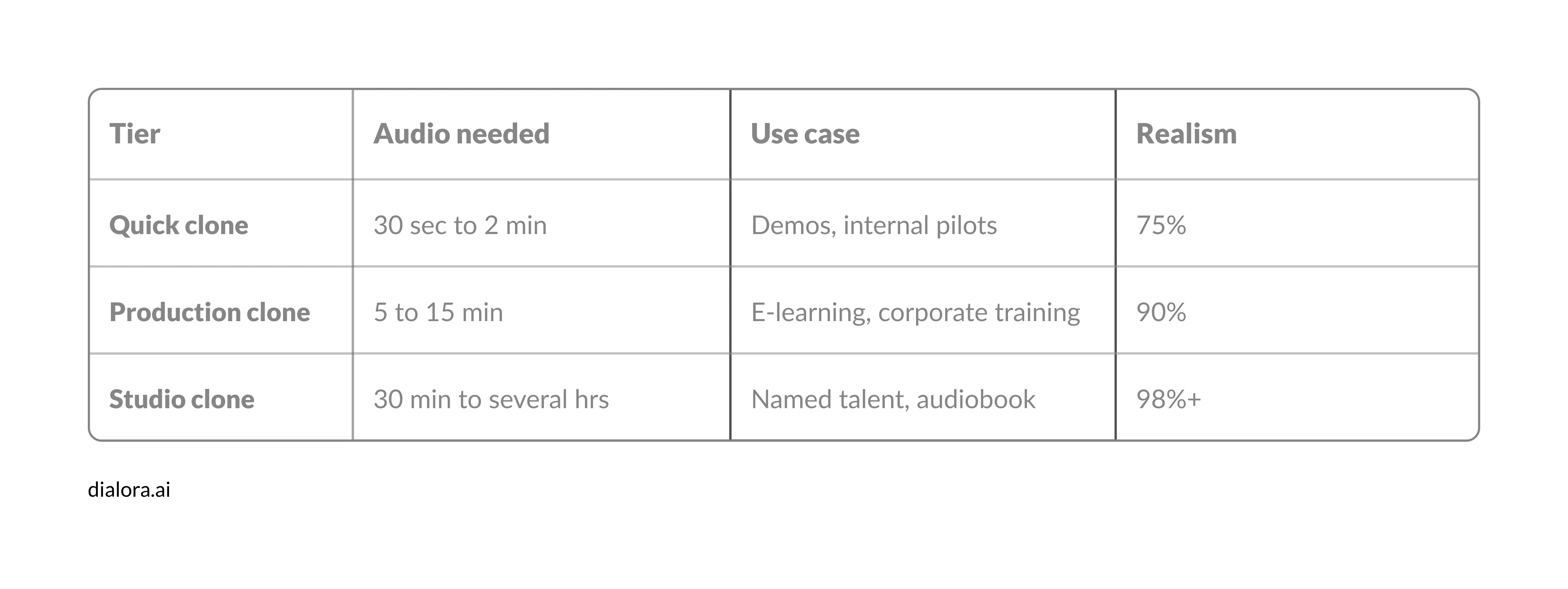
The right amount of training data isn't "as much as possible." It's the smallest sample that hits your quality bar without burning the talent's time.
How voice cloning fits e-learning and corporate training pipelines
The L&D and instructional design teams using AI voice in 2026 split into three production patterns. Each one has different demands on the underlying clone.
The first pattern is voice-over for e-learning at scale. Internal training, compliance modules, and onboarding sequences. The team records a 10-minute sample once, then generates every module's narration from text. The Tier 2 production clone is the right fit here, and the production rhythm reads like ordinary content ops. Script. Render. QA. Ship.
The second pattern is multilingual rollout. Dedicated voice-over translation software for e-learning has matured into the same neural-synthesis stack covered above, just with a translation layer in front. The L&D team writes in English, translates to Spanish, French, or Portuguese, and renders the localized audio in the same cloned voice. The voice stays consistent across languages. Listeners hear the same narrator regardless of which market they're in.
The third pattern is elearning voiceover for compliance-sensitive content (healthcare, finance, legal). The wrinkle here is the voice data collection AI policy. Some platforms train their general underlying machine learning audio models on the customer's voice samples by default. For regulated industries, this is a non-starter. The fix is enterprise-tier contracts that explicitly carve the customer's voice out of the general training pool.
This is where production discipline diverges from consumer voice cloning. The L&D team is not picking a tool. They're picking a vendor whose data handling matches their compliance posture.
What AI voice learning gets wrong and where the limits are
Modern voice cloning is impressive but not perfect. Four failure modes show up repeatedly in production.
The first is emotional range. A 90-second clone handles neutral narration well. It struggles with strong emotional cues (anger, deep sadness, sarcasm) that weren't represented in the training audio. The fix is to record samples covering the emotional range you'll actually deploy. This is also where AI voice adaptation earns its keep. The better platforms let you nudge the clone toward a specific emotion at render time instead of locking it to one tonal default.
The second is technical vocabulary. Models trained on general machine learning audio corpora sometimes mispronounce industry-specific terms. Pharmaceutical names. Medical procedures. Legal Latin. Engineering acronyms. The fix is a pronunciation lexicon submitted alongside the clone.
The third is voice drift across long sessions. Some platforms produce clones that subtly shift over a 60-minute narration. The pitch drifts up. The pace accelerates. The fix is to render in shorter segments and concatenate.
The fourth is security exposure. Because clones are so convincing, AI deep learning voice fraud detection is now a category of its own, because the same technology that lets you clone your own voice for training also lets attackers clone an executive's voice for fraud. Enterprise voice platforms ship with watermarking and detection layers to stay on the right side of this. Free-tier consumer tools usually don't.
The biggest voice cloning failures in 2026 aren't model quality issues. They're production discipline issues that good QA catches.
A note on personalization at scale
Personalized AI voice isn't just one cloned voice deployed across a company. The richer use case is per-listener personalization. A customer hears a slightly different version of the same script depending on their region, language, or past interactions. The underlying model is the same. The render parameters change. Most L&D teams don't need this yet. The teams shipping customer-facing AI voice in 2026 are starting to.
How AI voice learning powers Dialora's voice agents
Beneath every Dialora voice agent is the same architecture described above. Acoustic feature extraction, embedding storage, and real-time synthesis. The difference is that Dialora doesn't sell you a TTS tool with voice cloning. It sells you a voice agent that uses voice synthesis as one component of an end-to-end call workflow. Inbound call handling, outbound campaigns, appointment booking, CRM sync, all built on top of the voice layer. Teams looking to build an AI voice agent for customer support pick Dialora when the goal is operational outcomes (calls answered, bookings made, leads qualified). The voice cloning question matters for L&D. For customer-facing deployment, the right question is what the voice agent does with the voice, not how the voice was trained. Dialora's AI voice agent training for customer support workflows is configured against real call transcripts, not synthetic data, which is why escalation discipline holds up under production load.
See AI voice learning applied to a working business call
Where This Leaves L&D Teams Picking a Voice Cloning Approach
AI voice learning is no longer a question of whether the technology works. The acoustic feature extraction approach used by ElevenLabs, Resemble, and Microsoft now produces clones indistinguishable from source audio at the production tier. The questions that matter for L&D managers and instructional designers in 2026 are about workflow discipline. How much audio to record? Which emotional ranges to capture? Which pronunciation lexicon to ship? How to keep the clone consistent across 200+ training modules over 18 months. The technology has matured past the demo stage. The production discipline is where the wins now live.
Is AI voice cloning legal for corporate training?
Voice cloning is legal in the US when the speaker provides written consent for the specific use case. Several states have added explicit consent requirements for synthetic media. Enterprise voice cloning platforms now ship with audit logs and signed-consent workflows. Free-tier consumer cloning has caused regulatory issues and isn't suitable for commercial deployment.
L&D teams in 2026 aren't asking whether AI voice cloning works. They're asking how to keep it consistent over 200 modules. The technology cleared its quality bar two years ago. But what if you aren't an instructional designer? What if you are a business owner who just needs a reliable AI sales rep that picks up the phone, reasons through conversations, and closes deals without you having to build the tech stack yourself?
That is exactly what Dialora AI was built to do. Instead of just giving you a cloned voice, Dialora gives you a fully functional Gen-3 voice agent that books appointments and syncs natively with your CRM. Ready to see how a voice agent uses the same tech for real customer calls? Start your free trial today and watch your calendar fill up automatically.
Frequently Asked Questions
How does AI learn to recognize your voice?
AI voice learning works by extracting acoustic features from short audio samples (pitch, timbre, cadence, breath patterns) and training a neural model to reproduce them. The model stores a mathematical fingerprint of the speaker, not the audio itself. Modern systems can produce a passable clone where AI learns voice from 2 sentences of clean read text, though production-quality clones need 5 to 15 minutes of audio.
What data does AI use to learn your voice?
AI uses clean audio samples of the speaker reading varied text. Quality matters more than quantity. Studio-grade clones come from quiet rooms with consistent microphones. Background noise, reverb, and varied recording levels reduce clone quality. The text should cover the emotional and tonal range the clone will deploy.
Can AI clone your voice from 2 sentences?
Yes, technically. Modern systems can produce a recognizable clone from 30 seconds of audio (roughly 2 to 3 sentences). The clone won't match production quality, but it will sound like the speaker for short utterances. Studio-grade clones still need 5 minutes or more of clean audio.
How to choose a script to voice AI for e-learning?
For e-learning, pick a script-to-voice AI on three criteria. First, voice consistency across long modules (Tier 2 production clones win here). Second, data handling policy (does the vendor train on your samples by default). Third, multilingual support if you ship in more than one language. Most L&D teams pick on voice quality first and discover the policy issues during procurement.
How many samples does AI need to learn a voice?
For a passable clone, 30 seconds to 2 minutes of clean audio (roughly 1 to 2 paragraphs of read text). For production e-learning quality, 5 to 15 minutes (roughly 8 to 12 paragraphs covering varied sentence structures). For studio-grade applications, 30 minutes or more of high-quality recorded audio.
How to make your own RVC AI voice model?
How to make your own rvc ai voice model depends on the platform. RVC (Retrieval-based Voice Conversion) models typically need 10 to 30 minutes of clean audio, a GPU for training, and an open-source toolkit like RVC WebUI. The process is more technical than ElevenLabs or Resemble (which abstract the training step entirely) but gives you full ownership of the model weights. For commercial e-learning use, most teams pick a managed platform over self-hosting RVC because of the maintenance and compliance overhead.
How does Dialora handle voice training for customer support agents?
Dialora uses AI voice synthesis as one component of an end-to-end voice agent stack. The voice layer plugs into intent recognition, calendar integration, and CRM sync. Dialora is GDPR compliant and SOC 2 ready, with BAA available for healthcare customers. Voice training discipline follows the same tiers covered above.
Is AI voice cloning legal for corporate training?
Voice cloning is legal in the US when the speaker provides written consent for the specific use case. Several states have added explicit consent requirements for synthetic media. Enterprise voice cloning platforms now ship with audit logs and signed-consent workflows. Free-tier consumer cloning has caused regulatory issues and isn't suitable for commercial deployment.


