

TL; DR
- The best speech recognition API tools in 2026 split into two categories: real-time streaming APIs optimized for low latency and batch transcription APIs optimized for accuracy on long-form audio.
- Choosing the wrong ASR API locks you into accuracy and latency tradeoffs that only appear at production scale. Evaluation at development volume does not predict performance at production volume.
- For telephony architects and product owners building voice AI on top of an ASR layer, Dialora provides a complete AI voice agent platform. The ASR, NLU, telephony integration, and post-call sync are already built.
The engineering manager who ran the initial speech recognition API benchmark for a CCaaS platform rebuild chose the top-ranked option from a widely-cited 2024 comparison article. Accuracy score was strong. Latency at 10 concurrent requests was acceptable. At 200 concurrent requests under real telephony conditions, the p95 latency broke her SLA by 340 milliseconds. She had three weeks until the contract renewal with the enterprise client she had been building the system for.
The best speech recognition API tools in 2026 are not the ones with the best benchmark scores. They are the ones whose performance profile matches your production conditions.
This is the practical guide.
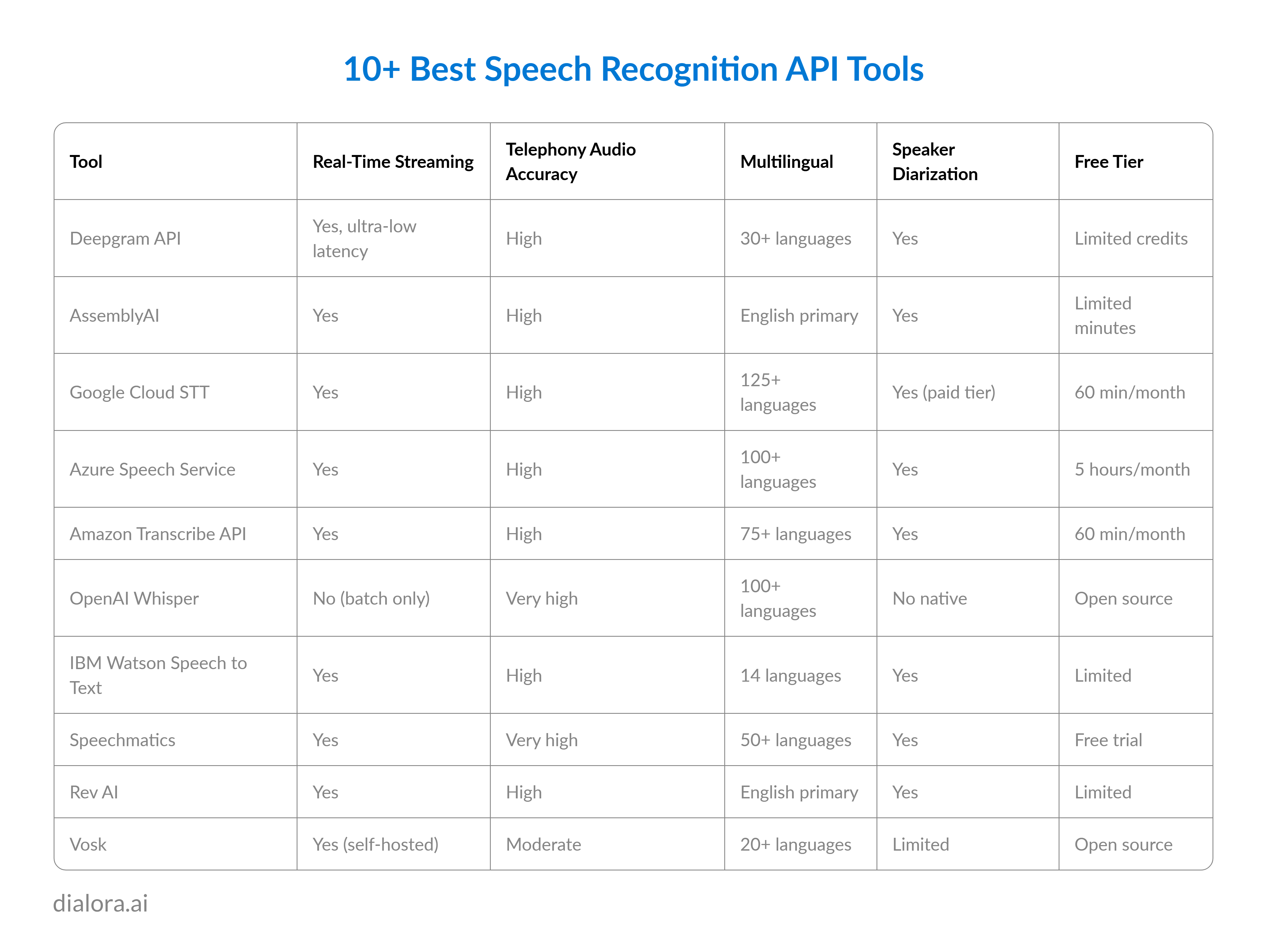
Best speech recognition API tools for 2026 include Deepgram, AssemblyAI, Google Cloud Speech-to-Text, Azure Speech Service, Amazon Transcribe, OpenAI Whisper, IBM Watson Speech to Text, and Speechmatics. Evaluation criteria include real-time latency, accuracy on telephony audio, language coverage, concurrent session limits, and speaker recognition support. The right API depends on your specific deployment conditions.
Why Does the Wrong Speech Recognition API Break at Production Scale?
The ASR API selection decision looks straightforward in a developer benchmark. Record a clean audio sample. Transcribe it. Compare accuracy scores. Pick the winner.
Production conditions are different. Telephony audio runs over VoIP at compressed bitrates. Callers speak with accents, background noise, and domain-specific vocabulary that generic models have not been trained on. Concurrent session limits on certain speech recognition API JavaScript and Python client libraries cause queuing delays that do not appear in single-session testing.
Speech recognition accuracy is a distribution, not a number. The headline accuracy figure from a benchmark covers clean, quiet, single-speaker audio. Real-time speech API performance under your conditions depends on your audio quality, your language mix, your domain vocabulary, and your concurrency profile.
The telephony architect who specified the ASR API for a mid-sized contact center had run the standard benchmark suite. His shortlist had three vendors. He did not test any of them against call recordings from his actual production call queue until three days before the go-live date. Two of the three vendors dropped from 94 per cent to 81 per cent accuracy on his caller audio. The third held at 91 per cent. That was the vendor he had initially ranked third on price.
Pro-tip:
Never pick a speech recognition API based on benchmark audio. Always test it on recordings from your actual callers.
Same problem, different vendor.
What Actually Differentiates the Best Speech Recognition APIs?
Real-time speech API performance separates the useful from the unusable for voice AI production. Five dimensions determine whether an ASR API survives your production conditions.
- Speech recognition accuracy on telephony audio. Not studio audio. Your callers' audio over your telephony stack.
- Real-time latency at production concurrency. Not 10 requests. Your peak concurrent session count.
- Multilingual speech recognition coverage. The languages your callers actually use, not the languages the vendor lists.
- Automatic speech recognition (ASR) streaming capability. Does it support word-by-word streaming or only full-utterance transcription?
- Speaker recognition API availability. Diarization for multi-speaker calls is essential for contact center and post-call analytics applications.
The vendors that score highest across all five are a short list. Most excel at two or three and compromise on the others.
10+ Best Speech Recognition API Tools in 2026
Note:
Android speech recognition API is available through Android SpeechRecognizer for native app use cases. The tools below cover server-side and cloud ASR for voice AI applications.
- Deepgram leads on real-time latency. The Nova-2 model achieves sub-300ms word latency on streaming audio, making it the default choice for live conversation applications. Speech recognition API Python and JavaScript SDKs are well-maintained.
- AssemblyAI leads on English accuracy and post-transcription intelligence features including topic detection, sentiment analysis, and chapter generation. Better suited for post-call analytics than real-time dialogue.
- Google Cloud Speech-to-Text leads in language breadth. 125+ languages with a well-documented API and strong how-to documentation for Python make it the default enterprise choice for multilingual deployments.
- Azure Speech Service integrates tightly with Microsoft infrastructure. The best choice for teams already running on Azure with Active Directory, Teams, or Dynamics integrations. Speech recognition API JavaScript support is strong.
- Amazon Transcribe API integrates cleanly with AWS Lambda and other AWS services. The natural choice for voice AI architectures already running on AWS.
- OpenAI Whisper sets the accuracy benchmark for batch transcription on noisy or accented audio. No managed real-time API. The open source model runs self-hosted. Best for post-call transcription workloads with accuracy requirements that commercial streaming APIs do not meet.
Pro-tip:
For live voice AI applications, latency matters more than peak accuracy. A 95 percent accurate response delivered in 800ms loses to a 91 percent accurate response delivered in 280ms.
Ready to See a Complete Voice AI Application Built on Top of ASR?
How to Use Google Speech Recognition API and When to Look Beyond It
Google Cloud Speech-to-Text is the most commonly used starting point for voice AI development because of its documentation quality and language coverage.
The limits are the limits. 60 minutes free per month. Enhanced model pricing adds up at production volume. Speaker diarization is a paid add-on. For teams building on the Google Cloud speech recognition API who hit production scale, the per-minute cost comparison against Deepgram or Azure becomes the dominant evaluation factor.
The API accepts audio input, runs it through a neural network trained on Google's voice data corpus, and returns timestamped transcription tokens. The streaming mode processes audio in chunks and returns partial results in real time.
The speech recognition benchmark that matters is the one you run on your own caller audio with your expected concurrency profile. Run that test before finalizing any vendor selection.
Ready to See a Voice AI Agent That Has Already Made the ASR Decision for You?
Dialora uses best-in-class automatic speech recognition as one layer of a complete AI voice agent platform. The platform handles inbound and outbound calls, appointment booking, intake qualification, and post-call CRM sync across 30+ countries. English, Spanish, French, Portuguese, and Turkish confirmed at production scale. The speech recognition benchmark you are running now is one layer of a four-layer problem. Dialora handles all four.
The speech recognition API decision is a production architecture decision, not a benchmark competition.
Test your audio. Test your concurrency. Then pick the tool.
The best speech recognition API tools are one layer. Dialora is the working application built on top of them. See It Handle a Real Call
Frequently Asked Questions
What is the most accurate speech recognition API?
Best speech recognition API tools for accuracy on noisy and accented telephony audio include Deepgram Nova-2, Google Cloud STT Enhanced, and Azure Speech Service. OpenAI Whisper achieves the highest accuracy in offline batch mode but does not support real-time streaming. Accuracy varies significantly by language, audio quality, and domain vocabulary. The most accurate API for your use case requires testing on your actual caller audio, not benchmark datasets.
Is the Google Speech Recognition API free?
The Google speech recognition API offers 60 minutes of standard model transcription free per month through Google Cloud. Enhanced models, streaming transcription, and medical speech models carry separate pricing. Usage above the free tier is billed per 15 seconds of audio processed. The free tier is useful for development and testing, but is typically exceeded within the first day of production call volume for contact centre applications.
How do I use the Google Speech Recognition API in Python?
Install the Google Cloud Speech Python library and authenticate with a service account JSON key. Initialize a speech client, configure a RecognitionConfig object with your encoding type, sample rate, and language code, then call recognize or streaming_recognize depending on whether you need batch or real-time processing. The speech recognition API Python library handles the gRPC connection and returns a response object with transcription results.
How does the Google Speech Recognition API work?
The Google Cloud Speech-to-Text API sends audio to Google's servers, where an automatic speech recognition model converts the audio waveform to text tokens. The model was trained on Google's proprietary voice data corpus covering multiple languages and acoustic conditions. Streaming mode processes audio in 100ms chunks and returns partial results as the audio is received. The API returns a confidence score with each transcription result.
Does Apple provide alternative recognition suggestions for speech recognition?
Apple's Speech Recognition framework, available through the iOS and macOS SFSpeechRecognizer API, returns alternative transcription results when enabled. The alternatives parameter in SFSpeechRecognitionRequest allows the API to return multiple hypothesis transcriptions ranked by confidence. This is used in accessibility applications and voice input interfaces to let users correct misrecognized speech without re-recording.


